(The following is the text of my presentation at the 2024 Mormon Transhumanist Association Conference in Provo, Utah, on April 13, 2024. I’ve also included a video recording of my presentation, if you would prefer to watch it rather than read it.)
My first AI image was something like this…

This blew my mind!
It was September 2022, and I had just bought an Nvidia graphics card for my computer and installed Stable Diffusion, a new open-source text-to-image generative AI software platform. In the prompt I simply typed the word “cat,” then set a couple other parameters, and clicked the button “generate.” Seconds later, a cat appeared on the screen. It was like pure magic, using a spell of words to conjure new realities into being.
Now, clearly it wasn’t perfect… but my computer had just seemingly “understood” a word I wrote, by performing millions of floating point calculations, and transformed it into a visual image of that very thing. It wasn’t just searching Google for a preexisting image of a cat, or retrieving it from a database somewhere. No, it was creating this image, on-the-fly, from scratch, based on its training of millions of images of cats. A deep learning neural network had essentially “learned” what that word “cat” represents, and using a latent diffusion model of that training data had generated a brand new image of a cat on my computer screen, never seen before. Never existing before.
A new art medium had been born.
It was early days, of course, and a four-eyed cat was more Picasso than Michelangelo, but I could see even then that this was going to be a very powerful new tool for creative expression, a new artistic medium, giving us powers that we had only dreamed of before, perhaps only imagined in our mind’s eye.
Fast forward just six months to March 2023, and we saw this image begin making the rounds on social media:

This was one of the first viral deep fakes using this new technology, I think made in Midjourney, which had become so powerful in its realism that it could fool people into thinking it was reality. And it did fool many. The writing was on the Facebook wall. As with any new technology, this could be used for good, as a new artistic tool for creativity and the benefit of humanity, but it could also be used for ill, for destruction, harm, misinformation, and deception of all kinds.
Today, I am just going to briefly discuss the positive side, and how I have used this new technology to facilitate my work as a designer and artist, but there are clearly many downsides that will also need to be addressed, and are being addressed, probably by some here today.
The visual arts have always been about creative expression, in using our creative skills and talents to bring to light our hopes and dreams, giving form to our deepest visions, communicating the otherwise ineffable, manifesting beauty, and expressing emotions deeper than words. Art, like religion, is a means of reifying the mystical, the abstract, the vague, the imaginative, the visionary, making concrete new worlds of being from our deepest inspirations. Indeed, it is a way to incarnate into physical reality what may have only been loosely glimpsed through the veil of the mind or imagination, piercing that veil to make it “on earth as it is in heaven.”
Some have argued that this new generative AI technology is not art at all, as it requires little to no skill to write a prompt and click a button. But I suggest this is like saying that photography is not art because anyone can tap the shutter button on their phone’s camera app, or painting is not art because anyone can pick up a paintbrush and smear paint on a canvas. It has also been said that this is not art because it has been “stolen” from artists of the past, and even some living today, since some models have been trained on their works. While I won’t go into that thorny subject today, and I do think we need to protect living artists, learning from the past to create a new present and better future is what creativity is all about, and it is what artists have done for ages. We should be thrilled that we can see new art pieces in the style of Van Gogh, or even see what Van Gogh himself may have looked like, based on his own self-portraits:

This kind of art isn’t generated by just writing a prompt and clicking a button. There is skill that goes into making good art using AI as another tool in the artist’s toolbox. I hope to give you a peek into my process, so you can see how I use this new technology, and the amazing new possibilities it offers to us.
One of the first commissions I did with this new art tool was reimagining a modern photographic version of an icon of the Hindu god Krishna and his wife goddess Radha, who are regarded as the masculine and feminine realities of God in some Hindu traditions. We may think of them like Heavenly Father and Heavenly Mother in the Mormon tradition.


In recent times Krishna has been depicted in art with a light blue skin tone, as on the left. But the classical iconography more anciently portrayed Krishna with a dark complexion, as on the right. Indeed, the Sanskrit origins of his name (Kṛṣṇa) signify “black,” “dark,” or “dark blue.” The patron who commissioned the art wanted a spiritual icon like this but with Krishna’s more ancient skin tone, to visually juxtapose with Radha’s luminous golden skin. This would not only showcase the duality of their divine union but also symbolize the complementary forces of light and dark, the yin and yang of existence, epitomizing the perfect union of opposites, and demonstrating that Love transcends all boundaries.
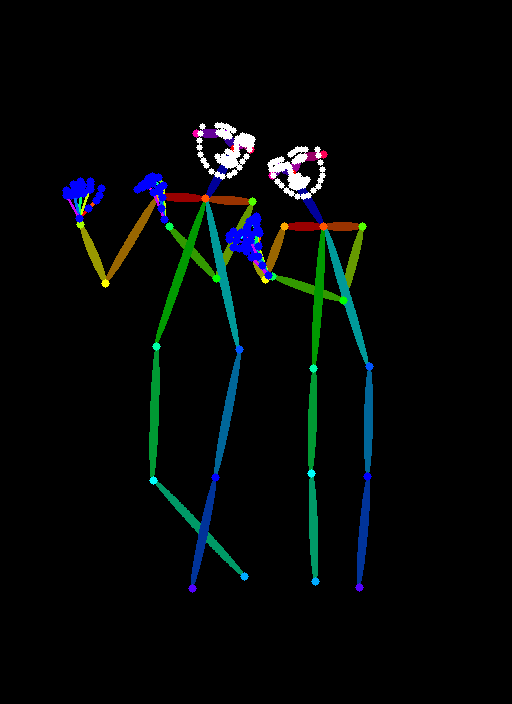
The first thing I did in recreating this icon with photorealism is configuring a process known as ControlNet OpenPose. This is a subsystem and extension to Stable Diffusion that allows you to condition the diffusion pipeline with specific poses, almost like puppetry, articulating the limbs of a skeleton, the hands, the face, etc. This helps guide the diffusion process to generate that pose or stance.
Once that was set up, I configured another subsystem called Regional Prompter. This allows you to specify prompts for different areas of an image. With an icon as complex as this one, a single prompt will never work to capture that complexity. Regional Prompter lets you establish boundaries that you can prompt independently, so the diffusion process will focus on those specific prompts for different areas of a single image. Here, for example, I could specify Krishna’s skin tone independently from Radha’s.
The first generations after this were low resolution images like this:


Gradually, the image was taking shape, but it was still low resolution, and many anomalies, such as her foot looking like a hand. AI has struggled particularly with hands and feet. It is much better today.
A significant next stage is inpainting. This means zooming into all of those details, masking each one, and prompting the system to generate new variations to fix or change them. There are many methods to help control and guide the output at this stage too. At the same time, I did a lot of manual editing work in Photoshop: painting, erasing, moving, shading, etc.
The last major part of the process is upscaling the art from low resolution to high, in this case over 33 megapixels. The process is similar to image-to-image, except that you can use a different ControlNet called Tile to add detail. This is quite different from simply enlarging an image in Photoshop. Here the AI will actually add contextual details to the image as it increases in resolution, so a leaf will actually look like a detailed leaf when it is blown up larger, rather than merely a big green blob.
After all of this work, which took several days, this is the final result:

So this is how we can use AI to make new art, depictions like this that were nearly impossible before have become possible, making our dreams and visions a reality, “on earth as it is in heaven.”
This is another recent commission I made, which went viral. It helps convey the spiritual message that “inasmuch as we do it unto the least of these, we do it unto Christ.”

Discover more from Thy Mind, O Human
Subscribe to get the latest posts sent to your email.
I also have discovered the incredible AI art. We are in a phenomenal age right now…. I love your art. You are seriously inspiring and good with it. I can’t get the correct prompts yet to do it like you are doing however. Really quite impressive ObiOne,….(GRIN!)